먼저 해당 포스팅은 CVPR 2018 논문 Deep Back-Projection Networks For Super-Resolution을 참고하여 작성하였음을 밝힙니다.
1. 논문의 개요

해당 논문이 개재될 당시 순방향(feed-forward) 신경망을 기반으로 한 SR 네트워크는 저해상도 입력 영상으로부터 고해상도 영상으로의 비선형적인 매핑을 학습하였습니다. 하지만 이러한 순방향의 접근법과는 대조적으로 인간의 시각 시스템은 feedback connection을 통하여 관련된 문제를 해결한다고 알려져있습니다. (feedback connection은 결과가 모델에 스스로 feedback을 보내는 연결관계를 의미한다고 합니다.) 이에따라 논문에서는 반복적인 up, down sampling layer들을 이용하여 각 단계마다의 projection error를 전달하는 Deep Back-Projection Network(DBPN)를 제안합니다. DBPN의 상호 연결된 up, down sampling의 각 단계는 서로 다른 유형의 이미지 저하와 고해상도 영상의 구성요소에 대한 정보를 포함합니다. 이러한 아이디어에 따라 각 단계에 걸친 feature map의 결합은 향상된 SR 결과를 재건하는데 상당한 도움이 됩니다. 8배율의 큰 스케일 펙터에 따른 DBPN의 SR 결과는 그림. 1과 같습니다.
2. 논문의 기여

해당 논문은 기여하는 바로써 네가지를 주장합니다. 첫 번째는 반복적인 error feedback 메커니즘을 제안한 것입니다. 향상된 결과를 위하여 DBPN에서는 up, down projection error를 계산하여, 초기 layer의 feature map을 제어하고 특정합니다. 두 번째는 상호 연결된 up-down sampling stage를 설계한 것입니다. 순방향 네트워크에서는 LR 영상의 특징만을 통해 HR 영상에 매핑하기 때문에 정보의 부족으로 그 결과가 만족스럽지 못합니다. 특히 큰 스케일 펙터의 경우 더욱 그러합니다. DBPN 모델에서는 upsampling layer를 통해서 HR feature map의 변형된 특징을 생성하는것 뿐만 아니라 down sampling layer를 통하여 LR 공간으로 projection 합니다. 이 과정은 그림. 2의(d)과 같습니다. 세 번째로는 up-down sampling stage 과정에서 생성된 feature map의 deep concatenation을 통하여 HR 영상을 재건한 것입니다. 이는 DBPN모델의 네트워크가 그림. 2의 (d)와 같이 up, down sampling layer를 통해 다양한 HR feature map의 구성요소와 영상의 degradation을 표현할 수 있기에 가능합니다. 마지막으로는 up-down sampling stage에 dense connection을 추가하여 정확도를 향상시킨 것입니다. 각 up-down sampling stage를 densely connection(그림. 2의 (d), 빨간 이음선)하여 feature map을 재사용함으로써 네트워크의 정확도를 향상시킵니다.
3. 관련 연구
3-1. Image super-resolution using deep networks
Deep Networks SR은 그림. 2와 같이 크게 4개의 타입으로 분류될 수 있습니다.
(a). Predefined upsampling : 이 타입은 operator가 보간법을 통해서 middle resolution(MR) 영상을 생성하는 방법입니다. 이 방법은 SRCNN을 통해서 소개되었습니다. SRCNN은 MR을 통해서 HR로의 비선형 매핑을 학습합니다. 이러한 접근법은 MR 영상으로부터 새로운 노이즈를 생성할 수 있습니다.
(b). Single upsampling : 이 타입은 일반적인 보간법 대신 간단하면서도 효과적으로 spatial resolution을 향상시키는 방법으로 upsampling layer를 두는 것을 제안합니다. 이 방법은 Fast SRCNN이라고도 불리는 FSRCNN을 통해서 소개되었습니다. 위 접근법으로는 네트워크의 용량의 제한으로 보다 복잡한 매핑을 학습하기 쉽지 않습니다.
(c). Progressive upsampling : 이 타입은 LapSRN을 통해서 제안된 방법으로 순방향의 네트워크에서 SR 영상들을 다양한 스케일로 점진적으로 재건하는 방식으로 진행됩니다. 단순하게 생각한다면 이는 LR 입력 영상에 single upsampling 네트워크를 쌓아놓은 것으로 볼 수 있습니다. 이러한 점에 덕분에 LapSRN은 얕은 네트워크를 가졌음에도 불구하고 큰 스케일 펙터에 대해서 좋은성능을 발휘합니다.
(d). Iterative up and downsampling : 이는 해당 논문에서 제안하는 타입입니다. 이 방법의 목표는 각기 다른 depth의 SR 영상의 sampling rate를 증가시키고, 각 stage의 reconstruction error를 잘 분산시켜 학습시키는 것입니다. 이를 통해 deep feature를 생성하며 다양한 up-down sampling operator를 학습함으로써 네트워크가 HR의 구성 요소를 보존할 수 있도록 합니다. (sampling rate..?)
3-2. Feedback networks
Feedback 네트워크는 한 스텝에서 입력과 출력 공간의 비선형 매핑을 학습하는 것이 아니라 다양한 스텝에서 예측 프로세스를 구성하여 self-correcting 과정을 수행합니다. Human pose estimation 분야에서는 반복적인 error feedback를 통해 현재 estimation을 개선하는데 적용한다고 합니다. (이 부분은 관련 논문을 더 공부한 후에 포스팅 하도록 하겠습니다.)
3-3. Adbersarial training
GAN과 같은 적대적 학습 방법은 다양한 image reconstruction 문제에 사용되어왔습니다. SR 분야에서는 이와 관련하여 pre-trained 네트워크로부터 추출한 high-level feature를 기반으로한 perceptual loss가 소개 되었고, single upsampling 방법으로 여겨지는 SRGAN이 제안되었습니다. (natural image manifold..?)
3-4. Back-projection
Back-projection은 reconstruction error를 최소화 하기 위한 효율적인 방법으로 잘 알려져있습니다. 원래 back-projection은 여러 입력 LR 영상을 위하여 고안된 것입니다. 하지만 입력 LR 영상이 주어졌을 때는 이를 다양한 uoperator를 통해서 upsampling 하고, reconstruction error를 반복적으로 계산하여 업데이트 하여 이를 적용할 수 있습니다. 이러한 방법을 기반으로 해당 논문에서는 상호 연결된 up and down sampling stage를 통하여 LR과 HR 영상간의 비선형적인 관계를 end-to-end로 학습하는 DBPN의 구조를 강조합니다.
4. Deep Back-Projection Networks
4-1. Projection units
$I^h$와 $I^l$을 각각 HR ($M \times N$) 과 LR ($M^' \times N^'$) 이미지라고 하겠습니다. 이때 $M^' < M$ 이고, $N^' < N$ 입니다. DBPN의 메인 block은 projection unit입니다. Projection unit은 up-projection을 통해서 LR feature map을 HR 영상에 매핑하거나, down-projection을 통해서 HR 영상을 LR영상에 매핑합니다.
그 중 up- projection unit은 아래의 표기. 1과 같이 정의되며, 수식의 표기는 다음의 설명과 같습니다.


Up projection unit은 이전에 계산한 LR feature map인 $L^{t-1}$ 을 입력으로 받아 intermediate HR feature map $H_0^t$으로 매핑합니다. 또한 이를 다시 LR feature map $L_0^t$에 매핑합니다(back-projection). LR feature map $L^{t-1}$과 reconstruct 된 $L_0^t$의 잔차를 의미하는 $e_t^l$를 HR에 다시 매핑하여 새로운 intermediate feature map $H_1^t$을 생성합니다. 이렇게 만들어진 두 intermediate feature map을 합산하여 up projection unit의 최종 출력이 산출됩니다. Down-projection unit 내부 각각의 표기는 이와 동일하지만, 그 순서에 따라 이 unit의 역할은 입력된 HR feature map $H^t$를 LR feature map $L^t$에 매핑하는 것입니다. 두 unit의 도식은 그림.3과 같습니다.

4-2. Dense projection units
DenseNet의 layer간의 dense connection pattern은 vanishing gradeint 문제를 해결한 것으로 잘 알려져 있습니다. 이에 따라 해당 논문에서는 DBPN과 더불어 projection unit간의 dense connection을 추가한 Dense DBPN(D-DBPN)을 소개합니다. 원래의 DenseNet에서 사용하는 dropout과 batch normalization은 feature map이 가지는 값의 범위의 유연성을 제거하기 때문에 SR에는 적합하지 않다고 합니다. (Enhanced deep residual networks for single image super-resolution, 이 부분은 체크하여 추후에 리뷰하도록 하겠습니다.) 그러므로 위 과정을 대신하여 1 $\times$ 1 convolution layer를 이용하여 pooling과 차원 축소를 수행한 후에 projection unit의 입력으로 사용합니다. D-DBPN에서 각 unit의 입력 feature map은 이전의 모든 unit의 출력 feature map의 concatenation으로 정의됩니다. 이에 따라서 dense up down-projection unit의 입력은 각각 $L^(\tilde{t})$, $H^(\tilde{t})$로 표현됩니다. Dense up, down-projection unit의 도식은 아래 그림. 4와 같습니다.

4-3. Network architecture

D-DBPN의 구조는 그림. 5와 같으며, 크게 세 부분으로 구분될 수 있습니다. 첫번째 부분은 initial feature extraction으로 input LR feature map $L^0$을 생성하는 역할을 수행합니다. 입력 LR 영상에 대하여 3 $\times$ 3 convolution과 1 $\times$ 1 convolution을 수행하며 각 projection unit에 입력될 feature map의 채널을 결정합니다. 두 번째 부분은 back-projection stage로 projection unit들이 연속되어 구성됩니다. 각 unit들은 이전 unit의 모든 출력을 입력으로 받습니다. 마지막 부분은 reconstruction입니다. HR 영상은 up-projection unit의 결과인 HR feature map ($H^1$, $H^2$, ... $H^t$) 들을 통해 생성됩니다.
5. Experiments Result
해당 논문에서는 스케일 펙터에 따라 projection unit의 필터의 크기를 조정하여 실험을 진행하였습니다.
- 2배율에서는 6 $\times$ 6 convolution layer에 stride, padding을 2로 주었습니다.
- 4배율에서는 8 $\times$ 8 convolution layer에 stride를 4로 하고, padding을 2로 주었습니다.
- 8배율에서는 12 $\times$ 12 convolution layer에 stride를 8로 하고, padding을 2로 주었습니다.
가중치의 초기값은 Delving deep into rectifiers: Surpassing human-level performance on imagenet classification논문을 참고하여 초기화 하였다고 합니다. 또한 데이터셋으로는 DIV2K, Flickr, ImageNet, Set5을 augmentaion 없이 사용하였습니다. LR 영상은 Bicubic 보간법을 통해 생성하였다고 합니다.
5-1. Depth analysis

Projection unit의 성능 평가를 위해 DBPN을 S ($T = 2$) , M ($T = 4$), L ($T = 6$) 모델로 분할하여 Set5 데이터셋으로 4배율을 학습하고 평가하였습니다. 그 결과는 그림.6과 같습니다. S 모델의 성능은 31.59db를 기록하며, DRCN, VDSR, LapSRN 보다 높은 PSNR을 보여주었습니다. M 모델은 성능은 31.74db를 기록하며 DRRN 보다 좋은 성능을 보여주었습니다. 마지막으로 L 모델은 다른 방법들의 PSNR보다 더 높은 31.86db를 기록하였습니다.

그림.7은 8배율에서 DBPN의 성능을 시각화 한 것입니다. 논문에서 주장한 바와 같이 큰 스케일 펙터의 경우에 DBPN의 효율성이 잘 드러납니다. 평가 조건은 4배율과 동일하며 결과는 그림.7과 같습니다. 하지만 이 경우 L 모델과 M 모델의 PSNR 차이는 0.04db로 경미한 것을 볼 수 있습니다.
5-2. Number of parameters
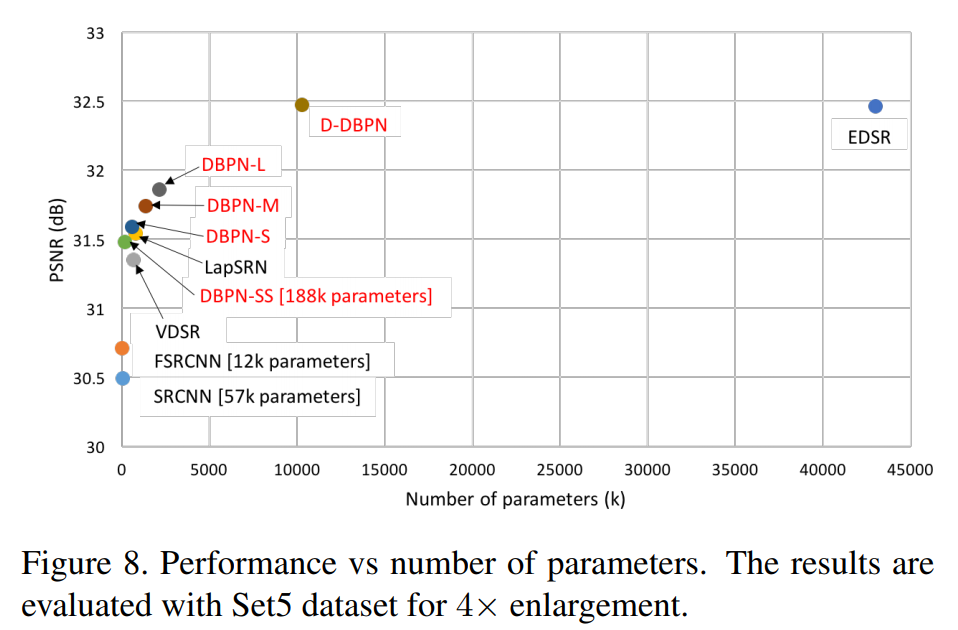
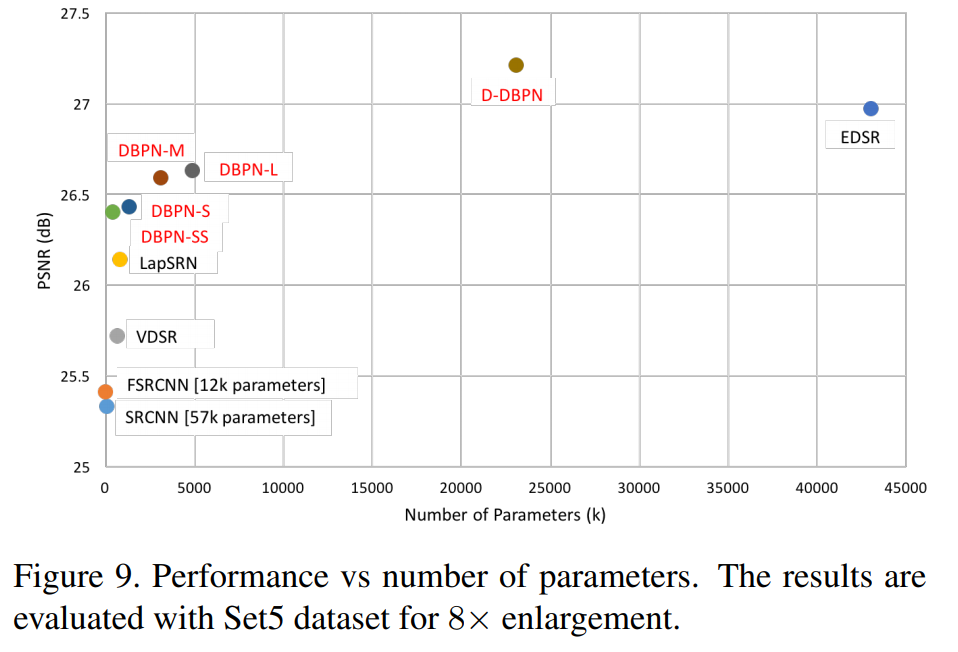
그림. 8은 DBPN의 S, M, L 모델과 D-DBPN 모델의 파라미터의 개수와 PSNR에 대한 산점도입니다. 이를 보면 확인 할 수있듯이 가중치 파라미터의 개수와 성능은 어느정도 tradeoff 관계가 성립하는것 같아보입니다. 가중치 파라미터의 개수는 채널의 크기에 큰 영향을 받습니다. DBPN의 경우 initial feature extraction 부분에서 2번의 convolution을 수행하는데 채널의 크기는 3, 128, 32 크기로 고정하였다고 합니다. 이는 projection unit의 convolution의 필터 개수 또한 32로 설정되어 수행되었다는 것을 의미합니다. 그림. 8의 DBPN-SS 모델은 initial feature extraction의 출력 feature map의 채널을 18로 설정한 가벼운 모델이라고 합니다. 위 모델의 경우 SRCNN, FSRCNN, VDSR보다 성능이 좋으며, VDSR보다 가중치 파라미터 또한 적은 것을 볼 수 있습니다.
5-3. Deep concatenation

각각의 projection unit은 각기 다른 HR 구성 요소의 디테일을 포함합니다. 이러한 unit들은 reconstruction step을 분산시키기 위해 사용됩니다. Deep concatenation은 앞서 정의한 back-projection의 $T$와 큰 연관이 있으며, 이는 projection unit을 통해 생성된 상세한 특징들이 그 결과의 질을 높일 수 있음을 그림. 9를 통해서 알 수 있습니다.
5-3. Comparison with the-state-of-the-arts

그림. 10은 DBPN과 SR 모델들의 4배율의 SR 결과에 대한 정성적 성능 평가 샘플에 해당합니다. 아래의 표. 1의 내용은 추후에 연구를 진행하며 레퍼런스 하기 위해 첨부해두도록 하겠습니다.

6. Conclusion
해당 논문은 single image SR을 위한 Deep Back-Projection Network을 제안하였습니다. 위 모델은 여러 up, down-sampling stage를 통해서 reconstruction error를 반복적으로 계산하여 업데이트 함으로써 각 stage에서의 sampling 결과를 개선해나갑니다. 이는 순방향의 신경망으로 SR 영상을 예측하는 방법론과는 차이가 있습니다. 5번 Experiments 부분에서 살펴볼 수 있듯이 8배율과 같은 큰 스케일 펙터에서 두드러진 성능을 보여주었습니다. 해당 논문을 포스팅하며 iterative back-projection과 deep connection의 효과에 대해서 잘 알아간 것 같습니다.
이렇게 DBPN : Deep Back-Projection Networks For Super-Resolution 논문을 살펴보았습니다. 질문이나 지적사항은 댓글로 남겨주시면 감사하겠습니다.



