먼저 해당 포스팅은 CVPR 2021 논문 Weakly-Supervised Physically Unconstrained Gaze Estimation을 참고하여 작성되었음을 밝힙니다. 해당 논문은 NVIDIA에서 발표된 논문으로 물리적으로 제약받지 않는 시선 추정을 위한 비지도 학습 프레임 워크를 제안합니다. Gaze Estimation Network는 세부적으로 "look at each other"(LAEO)라는 상황에 대하여 GT 레이블 없이 시선을 추정하기 위하여 정의된 5가지 손실함수를 정의합니다. 이를 통해 Gaze Estimation Network는 점차적으로 정확한 pseudo-3D gaze 레이블 생성하게 됩니다.
1. Introduction
3D gaze estimation을 위해 존재하는 대부분의 모델은 피사체와 카메라가 일정 거리 내에 위치해야 하며, 피사체가 정면을 응시해야 한다는 한계점을 가집니다. 이러한 문제를 해결하기 위하여 연구되는 방법론을 "physically unconstrained gaze estimation"이라 합니다. 위 논문에서는 앞서 언급한 문제점을 해결하기 위하여 weakly supervised한 방식으로 physically unconstrained gaze estimation을 수행하는 프레임 워크를 제안합니다. 여기서 weakly supervised learning이란 제한적인 데이터가 주어졌을 경우에 대응하는 레이블을 생성하기 위한 supervision을 제공하는데 사용되는 학습 방법을 의미합니다.

위 논문에서는 시선을 사람 사이의 자연스럽고 중요한 비언어적 소통 수단이라고 주장합니다. 이러한 소통은 비디오와 인터넷에서 흔히 찾아볼 수 있습니다. 위 아이디어로부터 기계가 사람들이 서로 상호작용하는 비디오를 관찰함으로써 시선을 추정하는 법을 학습할 수 없을까? 라는 질문에서 시작되었습니다. 이에 따라 LAEO(look at each other) 데이터로부터 strong gaze-related geometric constraint를 가정하고, 학습을 수행합니다. Gaze estimation 네트워크의 전체적인 도식과 접근 방법은 그림 1.과 같습니다. 해당 network는 2D LAEO의 sequential한 비디오 프레임 또는 단일 이미지를 입력으로 받습니다. 이때 학습에 이용되는 레이블은 annotation 된 얼굴의 바운딩 박스가 유일합니다. 하지만 만약 시선에 대한 GT 레이블이 존재한다면 추가적인 정보로서 학습에 이용될 수 있습니다.
2. Weakly-supervised Gaze learning
앞서 설명한 바와 같이 Gaze Estimation Network는 LAEO 영상을 이용하며, 대응하는 annotation에 따라 head pair를 crop하여 사용합니다. 여기서는 추가적인 시선 레이블은 이용하지 않는다고 가정하고 설명하겠습니다. LAEO 영상은 224 X 224 크기로 crop 되어 네트워크의 입력으로 사용됩니다. 이는 LSTM과 FC layer의 가중치 행렬의 크기는 고정적이기 때문입니다. 그림 2.(b)와 같이 ResNet-18 module을 통해 추출된 피쳐맵은 temporal과 static으로 구분됩니다. 만약 입력이 연속된 프레임(temporal)일 경우 추출된 LSTM module을 통해 연산되고, 단일 이미지(static)라면 LSTM module을 bypass하여 바로 FC layer로 입력됩니다. Gaze Estimation Network의 최종적인 연산 결과는 gaze vector와 uncertainty vector입니다. 이렇게 추출된 gaze vector와 uncertainty vector를 통해 손실 값을 계산하고, 그 값을 토대로 가중치 파라미터를 업데이트 해나갑니다.
단일 LAEO 이미지만으로는 피사체에 대한 정확한 depth가 추정되지 않으며, 카메라가 가진 파라미터 또한 알 수 없기 때문에 비지도 학습에 대한 supervision을 주기엔 충분하지 않습니다. 하지만 제안하는 손실함수 덕분에 학습이 가능해집니다. 이러한 이유로 아래의 학습을 weakly-supervised gaze learning이라 합니다. 추가적인 시선 레이블을 이용할 경우에는 semi-supervised gaze learning이 됩니다.
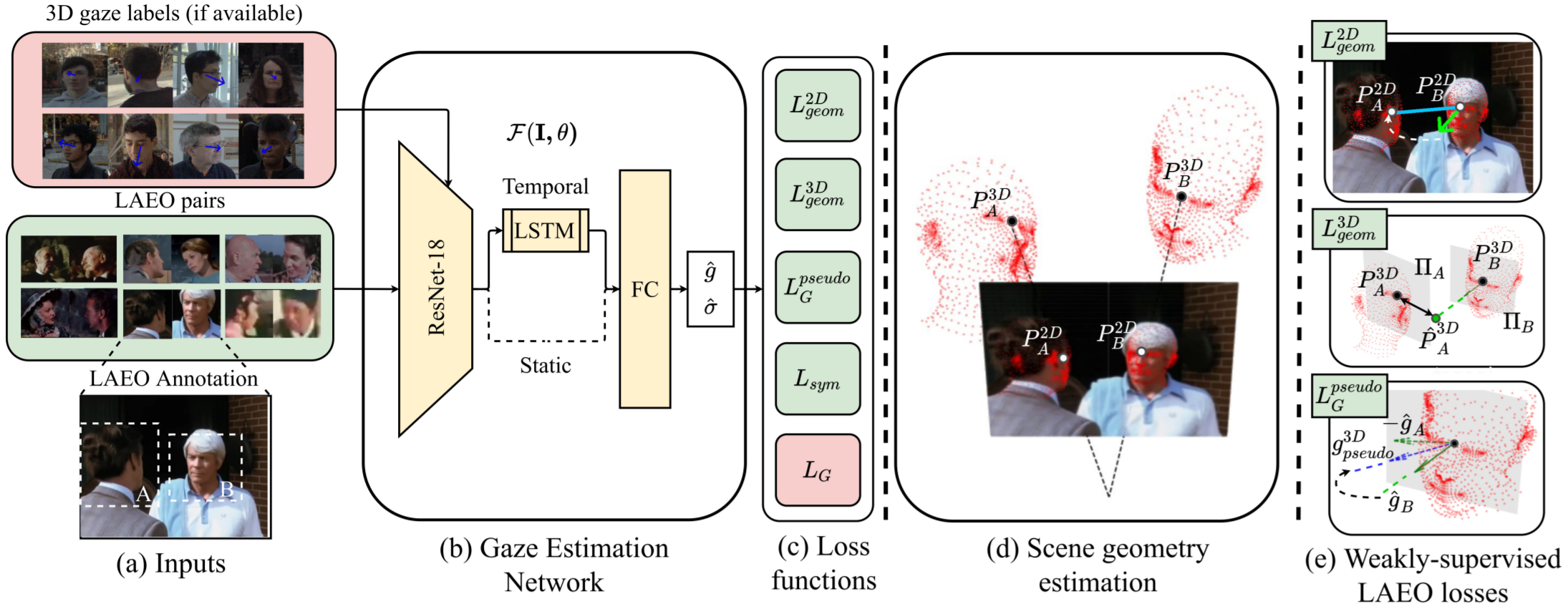
3. Loss Functions
위 논문의 핵심은 손실함수에 있다고 생각합니다. 제안하는 다섯 개의 손실함수를 통해 생성한 constraints 덕분에 gaze estimation network가 LAEO 데이터 만으로도 gaze vector를 학습할 수 있게 되었기 때문입니다. 논문에서 또한 gaze estimation을 위해 제안된 self-training procedure를 contribution으로 주장합니다.
손실 함수를 설명하기 위해 몇 가지 notation을 먼저 살펴보도록 하겠습니다.

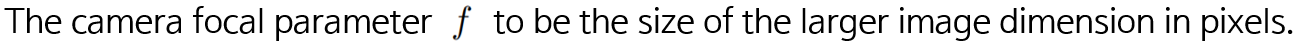
Cyclopean란 키클롭스라는 그리스 신화의 외눈박이 괴물을 의미합니다. Cyclopean eyes는 Alpha Pose를 통해 추출한 양쪽 동공의 좌표에 대한 중간 좌표(미간)에 해당합니다. 3D cyclopean eyes는 depth(z)를 추정하여 2D cyclopean eyes를 3D로 back project 하여 정의한다고 합니다. (카메라의 focal 파라미터인 f에 대한 수식은 저도 잘 모르겠습니다.)
3.1
3.2
3.3
3.4
3.5



