먼저 해당 포스팅은 PMLR 2015 논문 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift을 참고하여 작성하였음을 밝힙니다. 본 논문은 ICS(Internal Coveriate Shift)가 DNN(Deep Neural Network)의 효과적인 학습을 방해한다고 주장하며, 이를 해결할 수 있는 방법으로 배치 정규화(Batch Normalization)를 제안합니다. 추후에 개제된 How Does Batch Normalization Help Optimization? 논문에서 정말로 배치 정규화가 ICS 문제를 해결하는 가에 대한 의문이 제시되만, 배치 정규화가 DNN의 학습을 가속화 하며, 성능을 향상 시키는 것은 명확한 사실입니다.
1. Introduction
깊은 layer를 가지는 network일수록 학습이 어렵습니다. 해당 논문에서는 그 원인이 각 은닉층(hidden layer)의 입력에 해당하는 이전 은닉층의 출력 값의 분포가 역전파 과정을 통해 변화하기 때문이라고 주장합니다. 이러한 현상을 ICS(internal coveriate shift)라고 합니다. ICS 문제로 인해 SGD 방식을 통한 학습에서는 작은 학습률(learning rate)을 사용하게 되며, 가중치 파라미터의 초기화에 민감하게 반응하게 됩니다. 이를 해결하기 위해 각 미니 배치(mini-batch)를 정규화 한 후 평균과 분산을 조정하는 배치 정규화(batch normalization)를 제안합니다. 배치 정규화를 통해서 은닉층의 입력 값의 분포를 조정하여 안정적인 학습을 수행할 수 있으며, 학습 속도 또한 향상시킬 수 있습니다. 추가적으로 배치 정규화는 드랍아웃(drop out)과 같은 네트워크에 정규화 효과를 가져옵니다.
2. Normalization via Mini-Batch Statistics
그림 1.에서 $x$가 미니 배치의 입력 데이터라고 하였을 때 배치 정규화를 위해서는 아래와 같이 평균은 0, 분산이 1을 가지도록각 차원에 대해서 정규화 작업을 수행해주어야 합니다. 그 후 그림 2.와 같이 $\hat x$을 표준편차를 감마로 하고 평균을 베타로 하는 $y(k)$로 변환합니다.
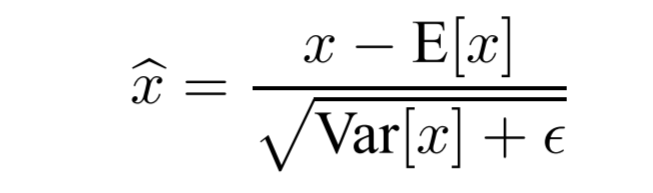


배치 정규화의 파라미터 감마와 베타는 학습되는 파라미터이므로 미니 배치 마다 역전파를 통해 업데이트 되며, 그 값은 저장됩니다. 검증 데이터 셋을 통해 네트워크의 성능을 확인할 때는 그 값이 사용됩니다. 이렇게 설명한 바와 같이 배치 정규화 과정은 그림 3.과 같습니다.

3. Experiments
3.1 Activations over time(MNIST)
이 실험에서는 MNIST 데이터 셋을 분류하여 배치 정규화의 효과를 확인하였습니다. 이에 따라 28x28 크기의 그레이 스케일 이미지를 입력으로 받는 100개의 채널의 FC layer 3개를 은닉층으로 하는 네트워크를 사용하였다. 그림 3-(a).는 학습 과정의 iteration에 따른 정확도(validation accuracy)를 나타낸 그래프 입니다. 배치정규화를 사용한 네트워크가 보다 더 짧은 iteration만에 수렴한 것을 볼 수 있으며, 정확도 또한 더 향상된 것을 볼 수 있습니다. 그림 3-(b,c).는 iteration에 따른 시그모이드 함수의 입력 값의 분포 변화를 나타냅니다 (위에서부터 사분위수를 차례로 배치). 배치 정규화를 사용한 네트워크가 학습 과정에서 은닉층 간 입력 분포를 안정하게 가져가는 것을 확인할 수 있습니다.

3.2 Accelerating BN Network(LSVRC2012)
배치 정규화는 학습에 있어서 더 높은 학습률을 사용할 수 있도록 한 바 있습니다. 그림 4(좌).는 inception 모델을 사용하여 LSVRC2012(imagenet) 데이터 셋을 학습하였을 때 iteration에 따른 정확도(validation)를 나타냅니다. 기존의 Inception 모델에서 사용한 학습률은 0.0015입니다. 배치 정규화 층을 네트워크에 추가하고 학습률에 변화를 주었을 때, 그 결과를 확인할 수 있습니다. 배치 정규화를 사용한 네트워크의 경우 학습률의 30배까지 실험한 것을 볼 수 있습니다. 이에따라 전체적인 수렴 속도가 향상되었으며, 각 은닉층의 학습이 안정적인 분포를 가지는 입력 값으로 진행되므로 정확도 또한 향상된 것을 확인할 수 있습니다.


이렇게 배치 정규화에 대해서 살펴보았습니다. 질문이나 지적 사항은 댓글로 남겨주시면 감사하겠습니다.


